|
|
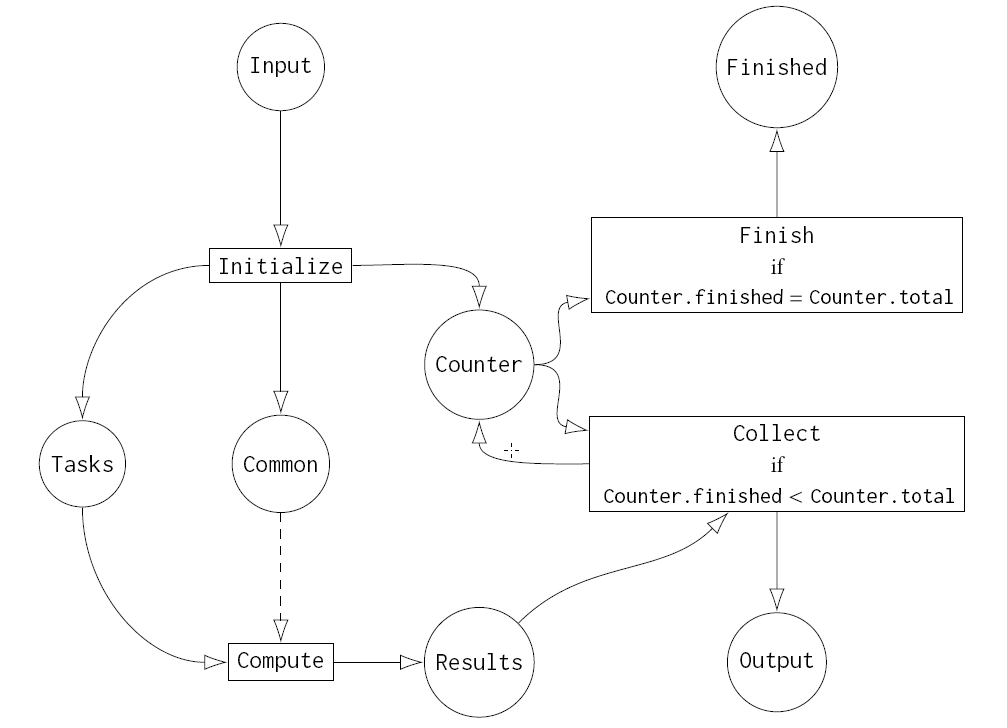
Singular/GPI-Space Framework
|

|
|
|
|
Publications
|
|
|
Massively Parallel Modular Methods in Commutative Algebra and Algebraic Geometry |
|
|
|
|
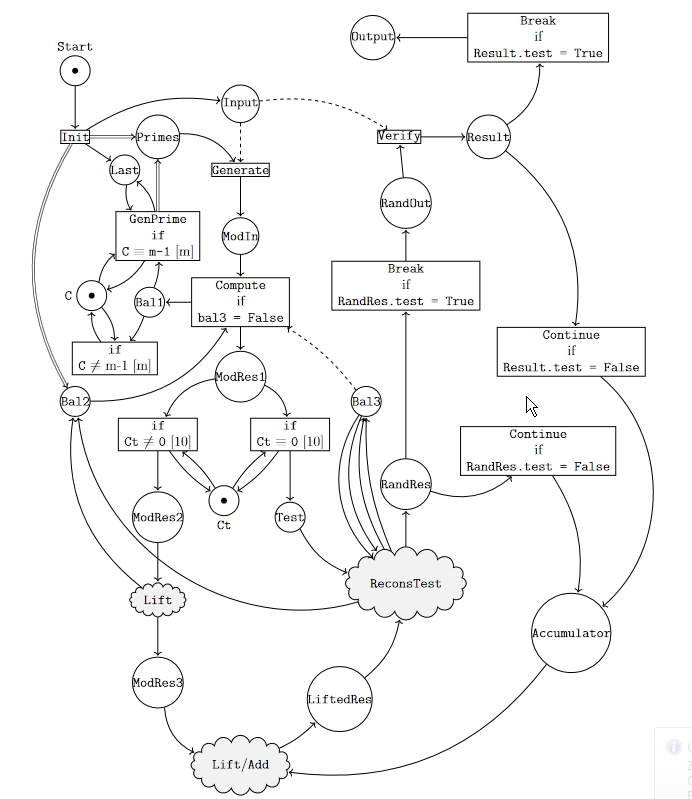 Computations over the rational numbers often encounter the problem of
intermediate coefficient growth. A solution to this is provided by
modular methods, which apply the algorithm under consideration modulo a
number of primes and then lift the results to the rationals. In arxiv.org/abs/2401.11606,
we present a
novel, massively parallel framework for modular computations with
polynomial data, which is able to cover a broad spectrum of applications
in commutative algebra and algebraic geometry. We demonstrate the
framework's effectiveness in Groebner basis computations over the
rationals and algorithmic methods from birational geometry. In
particular, we develop algorithms to compute images and domains of
rational maps, as well as determining invertibility and computing
inverses.
Computations over the rational numbers often encounter the problem of
intermediate coefficient growth. A solution to this is provided by
modular methods, which apply the algorithm under consideration modulo a
number of primes and then lift the results to the rationals. In arxiv.org/abs/2401.11606,
we present a
novel, massively parallel framework for modular computations with
polynomial data, which is able to cover a broad spectrum of applications
in commutative algebra and algebraic geometry. We demonstrate the
framework's effectiveness in Groebner basis computations over the
rationals and algorithmic methods from birational geometry. In
particular, we develop algorithms to compute images and domains of
rational maps, as well as determining invertibility and computing
inverses.
Our implementation modular-gspc is based on the Singular/GPI-Space framework,
which uses the computer algebra system Singular as computational
backend, while coordination and communication of parallel computations
is handled by the workflow management system GPI-Space, which relies on
Petri nets as its mathematical modeling language. Convenient
installation is realized through the package manager Spack. Relying on
Petri nets, our approach provides automated parallelization and
balancing of the load between computation, lifting, stabilization
testing, and potential verification. We use error tolerant rational
reconstruction to ensure termination as long as for a fixed computation
there exist only finitely many bad primes. Via stabilization testing,
our approach automatically finds with high probablity a minimal set of
primes required for the successful reconstruction.
We present timings to illustrate the potential for a game changing
improvement of performance over previous modular and non-modular
methods. In particular, we illustrate that the approach scales very well
with the number of processor cores used for the computation.
This paper is joint work with Dirk
Basson, Magdaleen
Marais, Mirko
Rahn, and Patrick
Hobihasina Rakotoarisoa.
|
|
|
|
|
Massively Parallel Computations in Algebraic Geometry
|
|
|
|
|
|
|
|
|
pfd-parallel, a Singular/GPI-Space package for massively parallel multivariate partial fractioning |
|
|
|
|
 Multivariate partial fractioning is a powerful tool for simplifying
rational function coefficients in scattering amplitude computations.
Since current research problems lead to large sets of complicated
rational functions, performance of the partial fractioning as well as
size of the obtained expressions are a prime concern. In
arxiv.org/abs/2104.06866
(Computer
Physics Communications Vol. 294, 2024, 108942),
we develop a large
scale parallel framework pfd-parallel for multivariate partial fractioning, which
implements and combines an improved version of Leinartas' algorithm and
the MultivariateApart algorithm. Our approach relies only on open
source software. It combines parallelism over the different rational
function coefficients with parallelism for individual expressions. The
implementation is based on the Singular/GPI-Space framework for massively parallel computer algebra, which formulates
parallel algorithms in terms of Petri nets. The modular nature of this
approach allows for easy incorporation of future algorithmic
developments into our package. We demonstrate the performance of our
framework by simplifying expressions arising from current multiloop
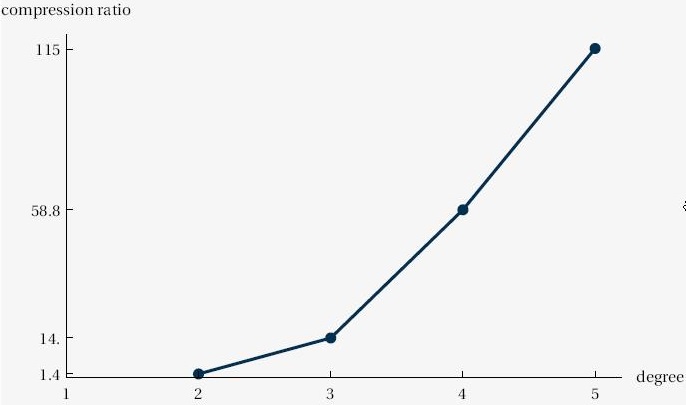
scattering amplitude problems. We discover
that the compression ratio increases with the complexity of the Feynman
integrals. See here
for the analytic result.
Multivariate partial fractioning is a powerful tool for simplifying
rational function coefficients in scattering amplitude computations.
Since current research problems lead to large sets of complicated
rational functions, performance of the partial fractioning as well as
size of the obtained expressions are a prime concern. In
arxiv.org/abs/2104.06866
(Computer
Physics Communications Vol. 294, 2024, 108942),
we develop a large
scale parallel framework pfd-parallel for multivariate partial fractioning, which
implements and combines an improved version of Leinartas' algorithm and
the MultivariateApart algorithm. Our approach relies only on open
source software. It combines parallelism over the different rational
function coefficients with parallelism for individual expressions. The
implementation is based on the Singular/GPI-Space framework for massively parallel computer algebra, which formulates
parallel algorithms in terms of Petri nets. The modular nature of this
approach allows for easy incorporation of future algorithmic
developments into our package. We demonstrate the performance of our
framework by simplifying expressions arising from current multiloop
scattering amplitude problems. We discover
that the compression ratio increases with the complexity of the Feynman
integrals. See here
for the analytic result.
This paper is joint work with Dominik
Bendle, Murray
Heymann, Mirko
Rahn, Lukas
Ristau, Marcel Wittmann, Zihao Wu, Yingxuan Xu
and Yang Zhang.
|
|
|
|
|
Module Intersection for the Integration-by-Parts Reduction of Multi-Loop Feynman Integrals |
|
|
|
|
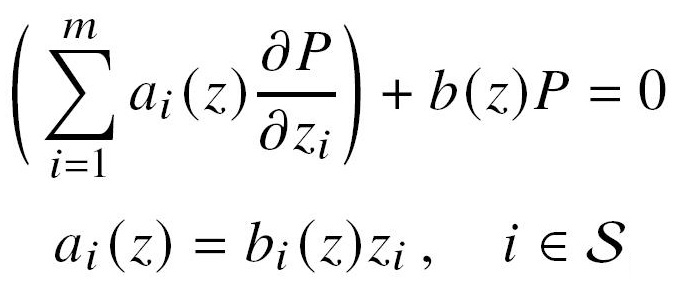 In
arxiv.org/abs/2010.06895
(to appear in PoS
(Proceedings
of Science), Proceedings of "MathemAmplitude 2019"
in Padova, Italy) we provide an
overview of the module intersection method for the the
integration-by-parts (IBP) reduction of multi-loop Feynman integrals.
The module intersection method, based on computational algebraic
geometry, is a highly efficient way of getting IBP relations without
double propagator or with a bound on the highest propagator degree. In
this manner, trimmed IBP systems which are much shorter than the
traditional ones can be obtained. We apply the modern, Petri net based,
workflow management system GPI-Space in combination with the computer
algebra system Singular to solve the trimmed IBP system via
interpolation and efficient parallelization. We show, in particular, how
to use the new plugin feature of GPI-Space to manage a global state of
the computation and to efficiently handle mutable data. Moreover, a
Mathematica interface to generate IBPs with restricted propagator
degree, which is based on module intersection, is presented in this
review.
In
arxiv.org/abs/2010.06895
(to appear in PoS
(Proceedings
of Science), Proceedings of "MathemAmplitude 2019"
in Padova, Italy) we provide an
overview of the module intersection method for the the
integration-by-parts (IBP) reduction of multi-loop Feynman integrals.
The module intersection method, based on computational algebraic
geometry, is a highly efficient way of getting IBP relations without
double propagator or with a bound on the highest propagator degree. In
this manner, trimmed IBP systems which are much shorter than the
traditional ones can be obtained. We apply the modern, Petri net based,
workflow management system GPI-Space in combination with the computer
algebra system Singular to solve the trimmed IBP system via
interpolation and efficient parallelization. We show, in particular, how
to use the new plugin feature of GPI-Space to manage a global state of
the computation and to efficiently handle mutable data. Moreover, a
Mathematica interface to generate IBPs with restricted propagator
degree, which is based on module intersection, is presented in this
review.
Janko
Böhm, Dominik
Bendle, Wolfram
Decker, Alessandro Georgoudis,
Franz-Josef Pfreundt,
Mirko
Rahn, and Yang Zhang.
|
|
|
|
|
A Massively Parallel Fan Traversal with Applications
in Geometric Invariant Theory
|
|
|
|
|
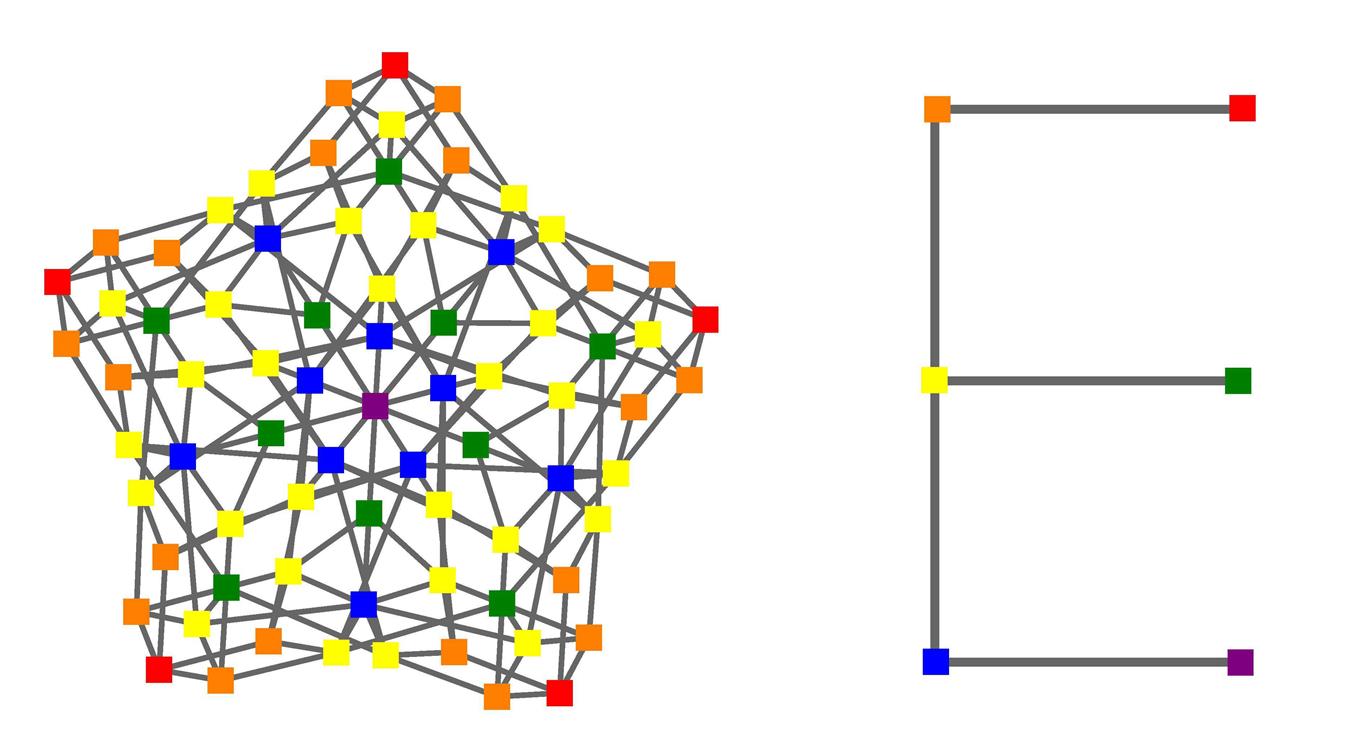 In computational algebraic geometry, fan traversals frequently occur at the
interplay of algebraic and combinatorial constructions.
In this article (in progress), we design and implement
a massively parallel approach to fan traversals. For
torus actions on affine varieties, we develop a massively
parallel algorithm for computing the associated GIT-fan.
Our fan traversal forms one key substep of this algorithm,
which in addition exploits symmetries of the problem.
Our implementation is based on the workflow manament
system GPI-Space, which uses Petri nets to model the
algorithm in the coordintation layer, while in the computation
layer we rely on the computer algebra system Singular.
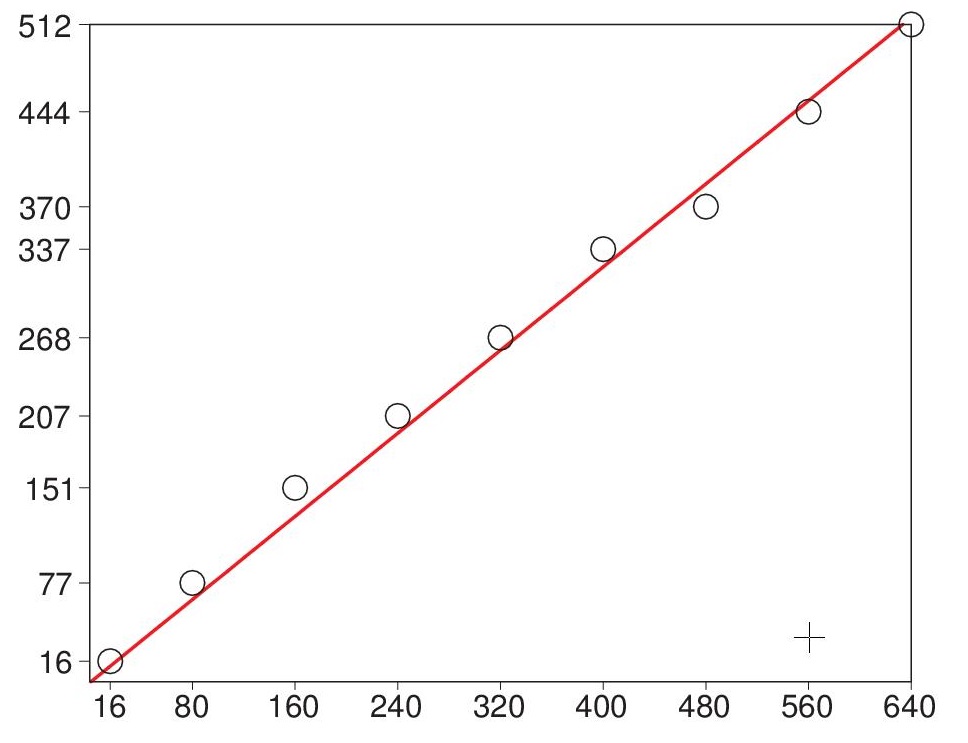
For the example of the Mori chamber decomposition of
the Deligne-Mumford compactification of the moduli space
of 6-pointed stable curves of genus zero, we provide
timings which show an impressive parallel efficiency
and scaling of the performance up to 640 cores (the
maximum we have tested).
In computational algebraic geometry, fan traversals frequently occur at the
interplay of algebraic and combinatorial constructions.
In this article (in progress), we design and implement
a massively parallel approach to fan traversals. For
torus actions on affine varieties, we develop a massively
parallel algorithm for computing the associated GIT-fan.
Our fan traversal forms one key substep of this algorithm,
which in addition exploits symmetries of the problem.
Our implementation is based on the workflow manament
system GPI-Space, which uses Petri nets to model the
algorithm in the coordintation layer, while in the computation
layer we rely on the computer algebra system Singular.
For the example of the Mori chamber decomposition of
the Deligne-Mumford compactification of the moduli space
of 6-pointed stable curves of genus zero, we provide
timings which show an impressive parallel efficiency
and scaling of the performance up to 640 cores (the
maximum we have tested).
Janko
Böhm, Anne
Frühbis-Krüger, Christian
Reinbold, and Mirko
Rahn.
|
|
|
|
|
Parallel Computation of tropical
varieties, their positive part, and tropical Grassmannians
|
|
|
|
|
 In the paper arxiv.org/abs/2003.13752
we present a massively parallel framework for computing
tropicalizations of algebraic varieties which can make
use of finite symmetries. We compute the tropical Grassmannian
TGr0(3,8),
and show that it refines the 15-dimensional skeleton
of the Dressian Dr(3,8) with the exception of 23 special
cones for which we construct explicit obstructions to
the realizability of their tropical linear spaces. Moreover,
we propose algorithms for identifying maximal-dimensional
tropical cones which belong to the positive tropicalization.
These algorithms exploit symmetries of the tropical
variety even though the positive tropicalization need
not be symmetric. We compute the maximal-dimensional
cones of the positive Grassmannian TGr+(3,8)
and compare them to the cluster complex of the classical
Grassmannian Gr(3,8).
In the paper arxiv.org/abs/2003.13752
we present a massively parallel framework for computing
tropicalizations of algebraic varieties which can make
use of finite symmetries. We compute the tropical Grassmannian
TGr0(3,8),
and show that it refines the 15-dimensional skeleton
of the Dressian Dr(3,8) with the exception of 23 special
cones for which we construct explicit obstructions to
the realizability of their tropical linear spaces. Moreover,
we propose algorithms for identifying maximal-dimensional
tropical cones which belong to the positive tropicalization.
These algorithms exploit symmetries of the tropical
variety even though the positive tropicalization need
not be symmetric. We compute the maximal-dimensional
cones of the positive Grassmannian TGr+(3,8)
and compare them to the cluster complex of the classical
Grassmannian Gr(3,8).
We also provide an extensive
collection
of data on the project.
Dominik
Bendle, Janko
Böhm, Yue Ren, and Benjamin
Schröter.
|
|
|
|
|
Integration-by-parts reductions of Feynman integrals using Singular and GPI-Space |
|
|
|
|
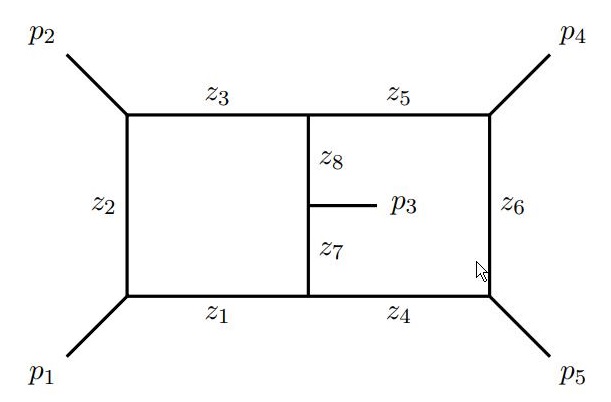 In the paper arxiv.org/abs/1908.04301
(Journal
of High Energy Physics 02 (2020) 79, 34 pp)
we introduce an algebro-geometrically motived integration-by-parts (IBP)
reduction method for multi-loop and multi-scale Feynman integrals, using a
framework for massively parallel computations in computer algebra. This
framework combines the computer algebra system Singular with the workflow
management system GPI-Space, which is being developed at the Fraunhofer
Institute for Industrial Mathematics (ITWM). In our approach, the IBP relations
are first trimmed by modern algebraic geometry tools and then solved by sparse
linear algebra and our new interpolation methods. These steps are efficiently
automatized and automatically parallelized by modeling the algorithm in
GPI-Space using the language of Petri-nets. We demonstrate the potential of our
method at the nontrivial example of reducing two-loop five-point nonplanar
double-pentagon integrals. We also use GPI-Space to convert the basis of IBP
reductions, and discuss the possible simplification of IBP coefficients in a
uniformly transcendental basis.
In the paper arxiv.org/abs/1908.04301
(Journal
of High Energy Physics 02 (2020) 79, 34 pp)
we introduce an algebro-geometrically motived integration-by-parts (IBP)
reduction method for multi-loop and multi-scale Feynman integrals, using a
framework for massively parallel computations in computer algebra. This
framework combines the computer algebra system Singular with the workflow
management system GPI-Space, which is being developed at the Fraunhofer
Institute for Industrial Mathematics (ITWM). In our approach, the IBP relations
are first trimmed by modern algebraic geometry tools and then solved by sparse
linear algebra and our new interpolation methods. These steps are efficiently
automatized and automatically parallelized by modeling the algorithm in
GPI-Space using the language of Petri-nets. We demonstrate the potential of our
method at the nontrivial example of reducing two-loop five-point nonplanar
double-pentagon integrals. We also use GPI-Space to convert the basis of IBP
reductions, and discuss the possible simplification of IBP coefficients in a
uniformly transcendental basis.
Dominik
Bendle, Janko
Böhm, Wolfram
Decker, Alessandro Georgoudis,
Franz-Josef Pfreundt,
Mirko
Rahn, Pascal Wasser, and Yang Zhang.
|
|
|
|
|
Massively parallel computations in algebraic geometry - not a contradiction |
|
|
|
|
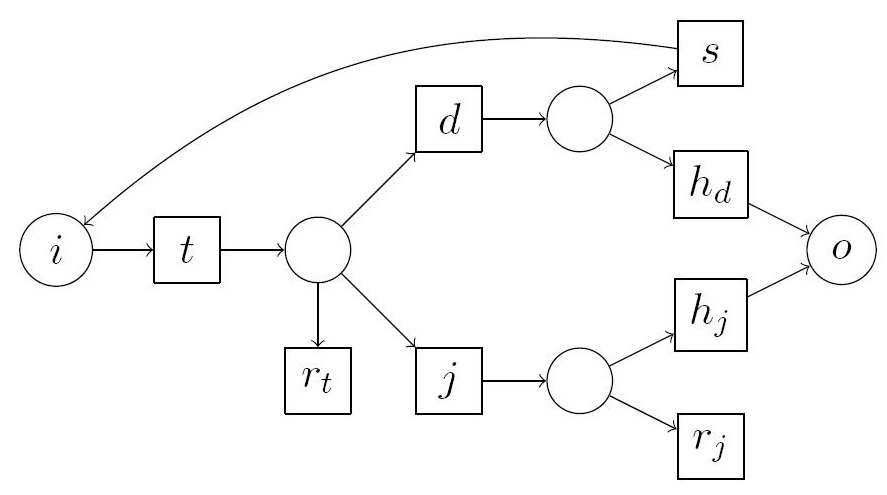
 The design and implementation of parallel algorithms is a fundamental task in
computer algebra. Combining the computer algebra system Singular and the
workflow management system GPI-Space, we have developed an infrastructure for
massively parallel computations in commutative algebra and algebraic geometry.
In the note arxiv.org/abs/1811.06092
(Computeralgebrarundbrief
64 (2019) 8-13), we give an overview on the current capabilities of this framework
by looking into three sample applications: determining smoothness of algebraic
varieties, computing GIT-fans in geometric invariant theory, and determining
tropicalizations. These applications employ algorithmic methods originating
from commutative algebra, sheaf structures on manifolds, local geometry, convex
geometry, group theory, and combinatorics, illustrating the potential of the
framework in further problems in computer algebra.
The design and implementation of parallel algorithms is a fundamental task in
computer algebra. Combining the computer algebra system Singular and the
workflow management system GPI-Space, we have developed an infrastructure for
massively parallel computations in commutative algebra and algebraic geometry.
In the note arxiv.org/abs/1811.06092
(Computeralgebrarundbrief
64 (2019) 8-13), we give an overview on the current capabilities of this framework
by looking into three sample applications: determining smoothness of algebraic
varieties, computing GIT-fans in geometric invariant theory, and determining
tropicalizations. These applications employ algorithmic methods originating
from commutative algebra, sheaf structures on manifolds, local geometry, convex
geometry, group theory, and combinatorics, illustrating the potential of the
framework in further problems in computer algebra.
Janko
Böhm, Anne
Frühbis-Krüger, and
Mirko
Rahn.
|
|
|
|
|
Towards Massively Parallel Computations in Algebraic Geometry |
|
|
|
|
 Introducing parallelism and exploring its use is still a fundamental
challenge for the computer algebra community. In high performance numerical
simulation, transparent environments for distributed
computing which follow the principle of separating coordination and computation
have been a success story for many years. In the paper arxiv.org/abs/1808.09727 (Foundations
of Computational Mathematics (2020)) we explore the
potential of using this principle in the context of computer algebra. More
precisely, we combine two well-established systems: The mathematical core algorithms
are implemented in the computer algebra system Singular, whose
focus is on polynomial computations, while coordination is handled by the
workflow management system GPI-Space, which relies on Petri nets as its
mathematical modeling language, and has been successfully used for coordinating
the parallel execution (autoparallelization) of academic codes as well as for commercial software
in application areas such as seismic data processing. The
result of our efforts is a major step towards a framework for massively
parallel computations in the application areas of Singular, specifically in
commutative algebra and algebraic geometry. As a first test case for this
framework, we have modeled and implemented a hybrid smoothness test for
algebraic varieties which combines ideas from Hironaka's celebrated
desingularization proof with the classical Jacobian criterion. Applying our
implementation to two examples originating from current research in algebraic
geometry, one of which cannot be handled by other means, we illustrate the
behavior of the smoothness test within our framework and investigate how the
computations scale up to 256 cores.
Introducing parallelism and exploring its use is still a fundamental
challenge for the computer algebra community. In high performance numerical
simulation, transparent environments for distributed
computing which follow the principle of separating coordination and computation
have been a success story for many years. In the paper arxiv.org/abs/1808.09727 (Foundations
of Computational Mathematics (2020)) we explore the
potential of using this principle in the context of computer algebra. More
precisely, we combine two well-established systems: The mathematical core algorithms
are implemented in the computer algebra system Singular, whose
focus is on polynomial computations, while coordination is handled by the
workflow management system GPI-Space, which relies on Petri nets as its
mathematical modeling language, and has been successfully used for coordinating
the parallel execution (autoparallelization) of academic codes as well as for commercial software
in application areas such as seismic data processing. The
result of our efforts is a major step towards a framework for massively
parallel computations in the application areas of Singular, specifically in
commutative algebra and algebraic geometry. As a first test case for this
framework, we have modeled and implemented a hybrid smoothness test for
algebraic varieties which combines ideas from Hironaka's celebrated
desingularization proof with the classical Jacobian criterion. Applying our
implementation to two examples originating from current research in algebraic
geometry, one of which cannot be handled by other means, we illustrate the
behavior of the smoothness test within our framework and investigate how the
computations scale up to 256 cores.
Janko
Böhm, Wolfram
Decker, Anne
Frühbis-Krüger,
Franz-Josef Pfreundt,
Mirko
Rahn, and Lukas
Ristau.
|
|
|
|
|
Embedded desingularization for
arithmetic surfaces -- toward a parallel implementation
|
|
|
|
|
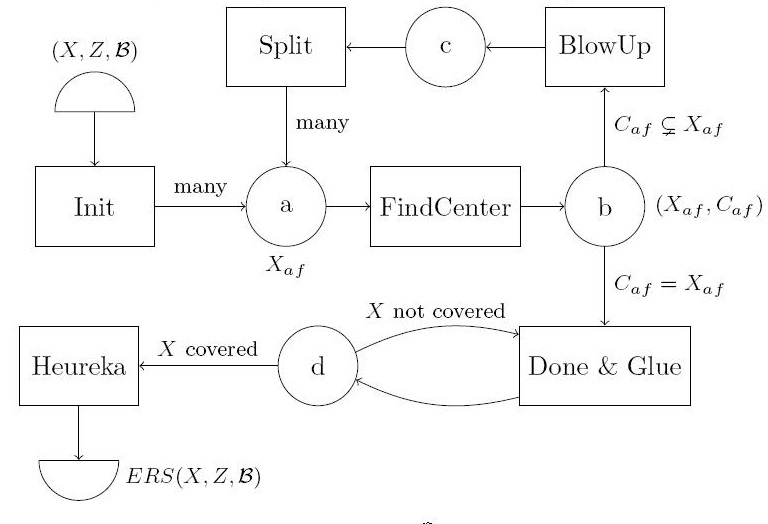 In the article arxiv.org/abs/1712.08131
(to appear in Mathematics of Computation),
we present an algorithmic embedded desingularization of arithmetic surfaces
bearing in mind implementability. Our algorithm is based on work by
Cossart-Jannsen-Saito, though our variant uses a refinement of the order
instead of the Hilbert-Samuel function as a measure for the complexity of the
singularity. We particularly focus on aspects arising when working in mixed
characteristics. Furthermore, we exploit the algorithm's natural parallel
structure rephrasing it in terms of Petri nets for use in the parallelization
environment GPI-Space with Singular as computational back-end.
In the article arxiv.org/abs/1712.08131
(to appear in Mathematics of Computation),
we present an algorithmic embedded desingularization of arithmetic surfaces
bearing in mind implementability. Our algorithm is based on work by
Cossart-Jannsen-Saito, though our variant uses a refinement of the order
instead of the Hilbert-Samuel function as a measure for the complexity of the
singularity. We particularly focus on aspects arising when working in mixed
characteristics. Furthermore, we exploit the algorithm's natural parallel
structure rephrasing it in terms of Petri nets for use in the parallelization
environment GPI-Space with Singular as computational back-end.
Anne
Frühbis-Krüger,
Lukas
Ristau, and Bernd
Schober.
|
|
|
|
 In the
In the